实验目标:实现一个由SysY(精简版C语言,来自翻译至RISC-V汇编的编译器,生成的汇编通过GCC的汇编器翻译至二进制,最终运行在模拟器qemu-riscv上
环境
安装wsl2 ubuntu22.04
wsl --update --pre-release
wsl --shutdown
wsl --list
wsl -d Ubuntu-22.04
Ubuntu配置镜像源
sudo cp /etc/apt/sources.list /etc/apt/sources.list.back
sudo vim /etc/apt/sources.list
清华源:
# 默认注释了源码镜像以提高 apt update 速度,如有需要可自行取消注释
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy main restricted universe multiverse
# deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy-updates main restricted universe multiverse
# deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy-updates main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy-backports main restricted universe multiverse
# deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy-backports main restricted universe multiverse
# 以下安全更新软件源包含了官方源与镜像站配置,如有需要可自行修改注释切换
deb http://security.ubuntu.com/ubuntu/ jammy-security main restricted universe multiverse
# deb-src http://security.ubuntu.com/ubuntu/ jammy-security main restricted universe multiverse
# 预发布软件源,不建议启用
# deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy-proposed main restricted universe multiverse
# # deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy-proposed main restricted universe multiverse
sudo apt update
sudo apt upgrade
Ubuntu安装docker
ubuntu安装软件的一些配置
添加gpg key(gpg(GNU Privacy Guard)加密工具提供的私钥)
#添加 Docker 官方 GPG key (可能国内现在访问会存在问题)
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg
# 阿里源(推荐使用阿里的gpg KEY)
curl -fsSL https://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg
添加apt(一个linux主流应用程序管理器)源
#添加 apt 源:
#Docker官方源
echo "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
#阿里apt源
echo "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://mirrors.aliyun.com/docker-ce/linux/ubuntu $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
更新配置
#更新源
sudo apt update
sudo apt-get update
安装docker
docker-ce(docker社区版)、docker-ce-cli(docker社区版命令行工具)、containerd.io(Docker容器运行时的核心组件之一,负责管理和运行容器)
sudo apt install docker-ce docker-ce-cli containerd.io
配置docker镜像
sudo vim /etc/docker/daemon.json
{
"registry-mirrors": ["https://docker.1ms.run"]
}
docker常用命令
(注:在docker刚安装时,由于只有root是其默认用户,所以要用sudo,而可以通过把其他用户添加到用户组,来在其他用户下使用)
#添加docker用户组(默认已存在)
sudo groupadd docker
#将当前用户添加到用户组
sudo usermod -aG docker $USER
#使权限生效
newgrp docker
docker命令
#查看Docker版本
sudo docker version
#查看所有容器
sudo docker ps -a
Docker 本身是一个容器化平台,而 systemctl 是 Linux 系统上用于控制系统服务的工具(属于 systemd 系统的一部分)。当 Docker 作为服务安装在 Linux 系统上时,可以通过 systemctl 来管理 Docker 守护进程(dockerd)的启动、停止和状态查看。
(service同理)
# 启动 Docker 服务
sudo systemctl start docker
# 停止 Docker 服务
sudo systemctl stop docker
# 重启 Docker 服务
sudo systemctl restart docker
# 查看 Docker 服务状态
sudo systemctl status docker
# 设置 Docker 服务开机自启
sudo systemctl enable docker
# 禁用 Docker 服务开机自启
sudo systemctl disable docker
# 重新加载 systemd 配置(修改服务配置后使用)
sudo systemctl daemon-reload
# 查看 Docker 服务的所有日志
sudo journalctl -u docker.service
# 查看 Docker 服务的实时日志
sudo journalctl -u docker.service -f
docker拉取开发环境镜像
这里面我把希冀网站下载的框架重命名为framework1并放在linux的 ~/exp/framework1中
这里面如果直接使用框架3会更好(一步到位),可惜学校目前只提供1
然后拉取进行并挂载目录
docker pull frankd35/demo:v3
#docker基本命令结构:docker run [选项] <镜像名> [命令]
#-it:交互式终端,允许进入容器执行命令
#-v:目录挂载,格式:-v <主机路径>:<容器路径>
#下面命令根据你的具体情况填写
docker run -it -v ~/exp/framework1:/coursegrader frankd35/demo:v3
前置配置
- 首先用vscode连接wsl:
.png)
解决下面报错:
VS Code 在 WSL 中误用了容器化的配置,wsl默认的不是你使用的系统,而是docker
[2025-04-14 03:34:33.017] Setting up server environment: Looking for /root/.vscode-server/server-env-setup. Not found.
[2025-04-14 03:34:33.017] WSL version: 6.6.84.1-microsoft-standard-WSL2 docker-desktop
[2025-04-14 03:34:33.018] WARNING: opening from cache https://dl-cdn.alpinelinux.org/alpine/v3.19/main: No such file or directory
[2025-04-14 03:34:33.018] WARNING: opening from cache https://dl-cdn.alpinelinux.org/alpine/v3.19/community: No such file or directory
[2025-04-14 03:34:33.018] libstdc++ is required to run the VSCode Server:
[2025-04-14 03:34:33.018] Please open an Alpine shell and run 'apk update && apk add libstdc++'
[2025-04-14 03:34:33.048] 有关启动问题的帮助,请转到 https://code.visualstudio.com/docs/remote/troubleshooting#_wsl-tips
解决方法:
wsl --set-default Ubuntu-22.04
wsl --shutdown
然后重启vscode进行操作
2. 然后用vscode启动对应的docker容器并attach
.png)
解决下面报错:
问题在于Docker 镜像的 Linux 版本(GLIBC 版本)(学校提供的镜像)和 vscode支持的 不匹配。而不是wsl的Linux版本和 vscode支持的 不匹配。
[19872 ms] Start: Run in container: '/root/.vscode-server/bin/4949701c880d4bdb949e3c0e6b400288da7f474b/bin/helpers/check-requirements.sh'
[20168 ms] Warning: Missing GLIBC >= 2.28! from /lib/x86_64-linux-gnu/libc-2.27.so
Error: Missing required dependencies. Please refer to our FAQ https://aka.ms/vscode-remote/faq/old-linux for additional information.
[20168 ms]
[20169 ms] Exit code 99
[20197 ms] Command in container failed: '/root/.vscode-server/bin/4949701c880d4bdb949e3c0e6b400288da7f474b/bin/helpers/check-requirements.sh'
[20199 ms] Warning: Missing GLIBC >= 2.28! from /lib/x86_64-linux-gnu/libc-2.27.so
Error: Missing required dependencies. Please refer to our FAQ https://aka.ms/vscode-remote/faq/old-linux for additional information.
[20200 ms] Exit code 99
解决方法:
vscode1.85.2便携版下载
https://vscode.download.prss.microsoft.com/dbazure/download/stable/8b3775030ed1a69b13e4f4c628c612102e30a681/VSCode-win32-x64-1.85.2.zip
注意使用便携版,wsl里安装的vscode插件的版本也有要换的
3. 修改CMakeLists.txt文件中的几个小bug。
在文件中找一个位置添加以下两行代码:
set(CMAKE_C_COMPILER "/usr/bin/x86_64-linux-gnu-gcc-7")
set(CMAKE_CXX_COMPILER "/usr/bin/x86_64-linux-gnu-g++-7")
修改原
#这种写法是不会生成调试信息的,也就不能启用gdb调试
set(CMAKE_CXX_FLAGS "-g") # 调试信息
set(CMAKE_CXX_FLAGS "-Wall") # 开启所有警告
为
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -g -Wall") # 调试信息和所有警告
- 在
/coursegrader目录下创建一个build文件夹,然后进入build文件夹,依次执行以下命令:
cmake ..
make
这样就可以完成项目的编译,编译的结果是在/coursegrader/bin目录下生成一个名为compiler的可执行文件和一些其它的中间文件。
5. 测试方法
- 单点测试
test中的testcase里面提供了一些基本sysy程序用于测试如00_main.sy
需要输入对应的参数执行compiler程序。程序会根据我们输入参数的不同执行不同的功能,对参数的解析过程在main.cpp文件中,可以自己研究一下。这里给出一个示例,比如我要执行00_main.sy测试点的riscv汇编代码生成功能:
./bin/compiler ./test/testcase/basic/00_main.sy -S -o ./myTest/test.out
第一个参数./bin/compiler是程序的路径,第二个./test/testcase/basic/00_main.sy是输入的文件路径,第三个-S是执行的阶段,第四个-o是输出文件选项,第五个./myTest/test.out是输出文件的路径和文件名。
编译->单点测试的全过程:
cd /coursegrader
rm -rf build/
mkdir build
cd ./build
cmake ..
make
cd /coursegrader
./bin/compiler ./test/testcase/basic/00_main.sy S -o ./myTest/test.out
- 集中测试
这里面的集中测试实际上就相当于把全部单点测试一次性测完,我原本还以为是对每个模块进行测试😓
框架中还提供了python脚本来进行集中测试,测试的脚本在test目录下。可以依次执行以下命令来进行测试:
cd /coursegrader/test
python3 build.py
python3 run.py s0
python3 test.py s0
- 调试方法
如果需要开启gdb断点调试,需要做一些配置
在项目目录下添加一个名为.vscode的文件夹,文件夹中创建两个文件,分别名为tasks.json和launch.json,前者是用于指导项目编译的,后者是用于指导debug工具连接的。
添加之后就可以直接使用vscode中的调试了,而不需要进行命令行操作了,注意这里面是对单点测试进行调试,需要调试哪个测试文件,就在launch.json将其取消注释
tasks.json
{
"version": "2.0.0",
"tasks": [
{
"label": "build",
"type": "shell",
"command": "cd ${workspaceFolder} && rm -rf build/ && mkdir build && cd ./build && cmake .. && make && cd ${workspaceFolder}",
"group": {
"kind": "build",
"isDefault": true
},
"problemMatcher": [
"$gcc"
],
"detail": "编译 /coursegrader 项目"
}
]
}
launch.json
{
"version": "0.2.0",
"configurations": [
{
"name": "Debug Compiler",
"type": "cppdbg",
"request": "launch",
"program": "${workspaceFolder}/bin/compiler",
"args": [
"./test/testcase/basic/00_main.sy",
// "./test/testcase/basic/01_var_defn2.sy",
// "./test/testcase/basic/02_var_defn3.sy",
// "./test/testcase/basic/03_arr_defn2.sy",
// "./test/testcase/basic/04_arr_defn3.sy",
// "./test/testcase/basic/06_const_var_defn2.sy",
// "./test/testcase/basic/07_const_var_defn3.sy",
// "./test/testcase/basic/08_const_array_defn.sy",
// "./test/testcase/basic/09_func_defn.sy",
// "./test/testcase/basic/10_var_defn_func.sy",
// "./test/testcase/basic/11_add2.sy",
// "./test/testcase/basic/12_addc.sy",
// "./test/testcase/basic/13_sub2.sy",
// "./test/testcase/basic/14_subc.sy",
// "./test/testcase/basic/15_mul.sy",
// "./test/testcase/basic/16_mulc.sy",
// "./test/testcase/basic/17_div.sy",
// "./test/testcase/basic/18_divc.sy",
// "./test/testcase/basic/20_rem.sy",
// "./test/testcase/basic/21_if_test2.sy",
// "./test/testcase/basic/22_if_test3.sy",
// "./test/testcase/basic/23_if_test4.sy",
// "./test/testcase/basic/25_while_if.sy",
// "./test/testcase/basic/26_while_test1.sy",
// "./test/testcase/basic/27_while_test2.sy",
// "./test/testcase/basic/29_break.sy",
// "./test/testcase/basic/30_continue.sy",
// "./test/testcase/basic/31_while_if_test1.sy",
// "./test/testcase/basic/32_while_if_test2.sy",
// "./test/testcase/basic/33_while_if_test3.sy",
// "./test/testcase/basic/35_op_priority1.sy",
// "./test/testcase/basic/36_op_priority2.sy",
// "./test/testcase/basic/37_op_priority3.sy",
// "./test/testcase/basic/40_unary_op.sy",
// "./test/testcase/basic/41_unary_op2.sy",
// "./test/testcase/basic/42_empty_stmt.sy",
// "./test/testcase/basic/45_comment1.sy",
// "./test/testcase/function/28_while_test3.sy",
// "./test/testcase/function/34_arr_expr_len.sy",
// "./test/testcase/function/38_op_priority4.sy",
// "./test/testcase/function/39_op_priority5.sy",
// "./test/testcase/function/43_logi_assign.sy",
// "./test/testcase/function/47_hex_oct_add.sy",
// "./test/testcase/function/48_assign_complex_expr.sy",
// "./test/testcase/function/49_if_complex_expr.sy",
// "./test/testcase/function/50_short_circuit.sy",
// "./test/testcase/function/51_short_circuit3.sy",
// "./test/testcase/function/52_scope.sy",
// "./test/testcase/function/55_sort_test1.sy",
// "./test/testcase/function/62_percolation.sy",
// "./test/testcase/function/64_calculator.sy",
// "./test/testcase/function/66_exgcd.sy",
// "./test/testcase/function/70_dijkstra.sy",
// "./test/testcase/function/73_int_io.sy",
// "./test/testcase/function/78_side_effect.sy",
// "./test/testcase/function/79_var_name.sy",
// "./test/testcase/function/89_many_globals.sy",
//"./test/testcase/function/95_float.sy",
// "-e",
// "-s2",
// "-o",
// "./myTest/test.ir",
"-S",
"-o",
"./myTest/test.s"
],
"stopAtEntry": false,
"cwd": "${workspaceFolder}",
"environment": [],
"externalConsole": false,
"MIMode": "gdb",
"setupCommands": [
{
"description": "Enable pretty-printing for gdb",
"text": "-enable-pretty-printing",
"ignoreFailures": true
}
],
"miDebuggerPath": "/usr/bin/gdb",
"preLaunchTask": "build",
"logging": {
"engineLogging": true
}
}
]
}
- 代码框架
下面是框架3的目录结构,而非框架1
coursegrader
├─ .gitignore # git上传忽视文件列表
├─ .vscode # gdb调试配置文件
│ ├─ c_cpp_properties.json
│ ├─ launch.json
│ ├─ settings.json
│ └─ tasks.json
├─ CMakeLists.txt # CMake配置文件
├─ RAEDME.assets # README图像资源
├─ README.md # 项目说明文件
├─ bin # 编译生成的二进制文件
│ ├─ compiler # 目标文件
│ ├─ libBackend.a
│ ├─ libFront.a
│ ├─ libIR.a
│ ├─ libTools.a
│ └─ libjsoncpp.a
├─ build # CMake构建目录,需自己创建
├─ include # 头文件目录,结构和源文件目录差不多
├─ lib # 静态链接库,如果要用静态连接文件记得重命名
│ ├─ libIR-x86-linux.a
│ ├─ libIR-x86-win.a
│ ├─ libIR.a
│ ├─ libTools-x86-linux.a
│ ├─ libTools-x86-win.a
│ └─ libTools.a
├─ main.cpp # 主程序,注释包含了编译的参数分析
├─ src # 源文件目录
│ ├─ backend # 后端
│ │ ├─ generator.cpp # 目标代码生成器
│ │ └─ rv_def.cpp # riscv汇编相关定义
│ ├─ front # 前端
│ │ ├─ abstract_syntax_tree.cpp # 抽象语法树定义
│ │ ├─ lexical.cpp # 词法分析器实现
│ │ ├─ semantic.cpp # 语义分析器实现
│ │ ├─ syntax.cpp # 语法分析器实现
│ │ └─ token.cpp # 词法单元定义
│ ├─ ir # IR相关定义
│ │ ├─ ir_function.cpp
│ │ ├─ ir_instruction.cpp
│ │ ├─ ir_operand.cpp
│ │ ├─ ir_operator.cpp
│ │ ├─ ir_program.cpp
│ │ └─ type.cpp
│ ├─ third_party # 第三方库,生成json对象用的
│ └─ tools
│ ├─ ir_executor.cpp # ir评测机实现
│ └─ sylib.c # 运行时库实现
└─ test
├─ __pycache__ # python创建的临时文件
├─ build.py # 自动构建脚本
├─ log.txt # 脚本报错信息
├─ output # 脚本运行结果
├─ ref # 参考运行结果
├─ run.py # 执行脚本
├─ score.py # 评分脚本
├─ sylib-riscv-linux.a
├─ sylib.h # 运行时库头文件
├─ test.py # 其实就是前三个脚本的合集,会自动调用前三个脚本,一条龙服务
└─ testcase # 测试点源文件
词法分析
词法分析的实现进行在lexical.cpp中
Scanner是扫描器,其职责是将字符串输入转化为Token串,词法分析实际上就是实现一个Scanner
词法分析的输入是源程序,输出是token串。主要的工作可以分为两个部分,一是预处理器,用于删除注释;二是DFA有限状态机,通过状态转换来输出对应的token串。
当我们实现完了预处理和DFA后,在下面TODO写调用语句进行调用

预处理器
预处理器负责处理单行注释和多行注释如:
//
/*
*/
我们需要自行实现预处理函数
我这里准备实现一个预处理函数std::string preproccess(std::ifstream &fin)
这里我们处理的逻辑是:
1、对于输入流std::ifstream &fin,我们进行逐行处理
std::string res; //这里是我们最终要返回的处理结果
std::string curLine;//当前处理行
while(std::getline(fin, curLine)){
}
2、我们用一个bool值isInsideComment表示当前在一个多行注释内部(即已经出现了/*,但还未出现*/)(注:我们为了便于处理,多行注释在同一行出现注释与其终止符和不同行出现注释与其终止符的处理逻辑是分开的)
bool isInsideComment=false;
这里我们分为在多行注释内部和非多行注释内部分别处理
3、如果我们在多行注释内部
我们需要判断是否存在终止符*/,如果不存在我们就直接跳过该行(因为没有有效字符了),如果存在我们就删掉终止符前的字符,然后对余下的字符进行处理
int endPos = 0; // 记录多行注释结束符位置
if (isInsideComment) // 如果在多行注释内部
{
endPos = curLine.find("*/"); // 寻找该行是否存在多行注释结束符
if (endPos != std::string::npos) // 如果存在(find函数在找不到指定值得情况下会返回string::npos)
{ // 删除结束符之前包括结束符的内容
isInsideComment = false;
curLine.erase(0, endPos + 2);
}
else
continue; // 如果不存在,忽视当前行
}
std::string::find 函数
size_type find(const basic_string& str, size_type pos = 0) const; 查找从位置 pos 开始的与 str 相等的第一个子字符串。
4、如果我们不在多行注释内部
因为我们可能在同一行包含多个注释符号,所以我们循环处理
这里我们分为三种情况:
- 只有单行注释:我们直接删去第一个找到的单行注释后的全部内容
- 只有多行注释:这里我们只要没有遇到终结符,无论遇到多少个多行注释
/*都只有第一个有效;终结符同理,只有遇到第一个匹配。这里我们分为同一行内有终结符(删除之间的),没有终结符(删除起始符之后的) - 有单行注释和多行注释:主要看谁在前面
while (curLine.find("//") != std::string::npos || curLine.find("/*") != std::string::npos){ // 当这一行还存在单行注释或者多行注释起始符
int sinPos = curLine.find("//"); //第一个单行注释的位置
int startPos = curLine.find("/*"); //第一个多行注释起始符的位置
endPos = curLine.find("*/", startPos + 2); //第一个多行注释终结符的位置
if (sinPos != std::string::npos && startPos == std::string::npos){ // 1、如果只存在单行注释
curLine.erase(sinPos); // 删除单行注释后的所有内容
}
else if (sinPos == std::string::npos && startPos != std::string::npos) // 如果只存在多行注释起始符
{
if (endPos != std::string::npos) // 2、如果本行存在终止符
curLine.erase(startPos, endPos - startPos + 2); // 删除多行注释
else // 如果本行不存在终止符
{
isInsideComment = true; // 标记在多行注释内部
curLine.erase(startPos); // 删除多行注释起始符
}
}
else // 3、如果多行注释和单行注释同时存在
{
if (sinPos < startPos) // 如果单行注释在前
curLine.erase(sinPos); //删除之后的
else{ // 如果多行注释在前
endPos = curLine.find("*/");
if (endPos != std::string::npos) // 同时本行存在终止符
curLine.erase(startPos, endPos - startPos + 2); // 删除多行注释
else // 本行不存在终止符
{
isInsideComment = true; // 标记在多行注释内部
curLine.erase(startPos); // 删除多行注释起始符
}
}
}
}
5、将处理后的行加入结果
res += curLine + "\n";
最后return即可
DFA
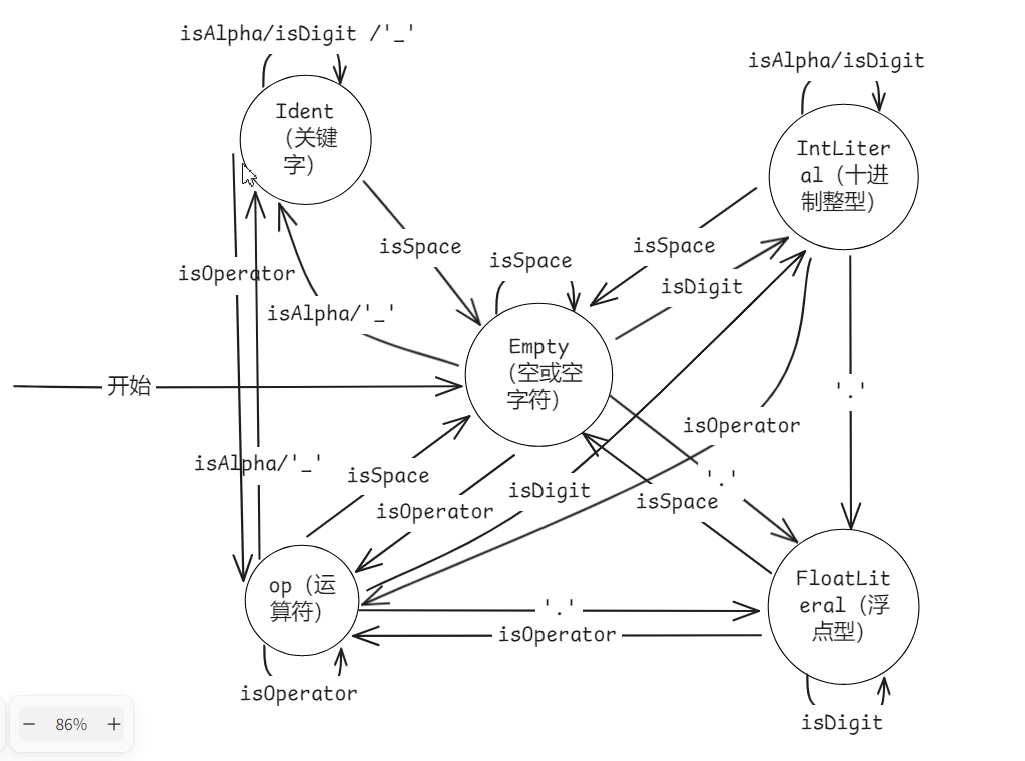
我们DFA的实现代码在下面TODO书写

DFA状态机的任务就是对预处理过后的源程序进行分词。DFA会逐个读入处理后的源程序,然后根据事先给定的转移函数转移到下一个状态,某些转移函数会进行输出
注意:我们的状态在lexical.h中定义
注意我们的关键字和操作符TokenType在token.h中定义
我们这里面主要主要使用case和if来进行状态的转换
1、我们需要先绘制出DFA状态机(别直接用我的)
2、实现一些前置函数
bool isSpace(char c){
return isspace(c);
}
bool isAlpha(char c){
return isalpha(c);
}
bool isOperator(char c){
return c == '+' || c == '-' || c == '*' || c == '/' ||
c == '%' || c == '<' || c == '>' || c == '=' ||
c == ':' || c == ';' || c == '(' || c == ')' ||
c == '[' || c == ']' || c == '{' || c == '}' ||
c == '!' || c == '&' || c == '|' || c == ',';
}
frontend::TokenType getIdentType(std::string s){ // 返回关键字类型
if (s == "const")
return frontend::TokenType::CONSTTK;
else if (s == "int")
return frontend::TokenType::INTTK;
else if (s == "float")
return frontend::TokenType::FLOATTK;
else if (s == "if")
return frontend::TokenType::IFTK;
else if (s == "else")
return frontend::TokenType::ELSETK;
else if (s == "while")
return frontend::TokenType::WHILETK;
else if (s == "continue")
return frontend::TokenType::CONTINUETK;
else if (s == "break")
return frontend::TokenType::BREAKTK;
else if (s == "return")
return frontend::TokenType::RETURNTK;
else if (s == "void")
return frontend::TokenType::VOIDTK;
else // 如果都不是,说明是名称
return frontend::TokenType::IDENFR;
}
frontend::TokenType getOpType(std::string s)//判断是不是单字符宽的操作符
{
if (s == "+")
return frontend::TokenType::PLUS;
else if (s == "-")
return frontend::TokenType::MINU;
else if (s == "*")
return frontend::TokenType::MULT;
else if (s == "/")
return frontend::TokenType::DIV;
else if (s == "%")
return frontend::TokenType::MOD;
else if (s == "<")
return frontend::TokenType::LSS;
else if (s == ">")
return frontend::TokenType::GTR;
else if (s == ":")
return frontend::TokenType::COLON;
else if (s == "=")
return frontend::TokenType::ASSIGN;
else if (s == ";")
return frontend::TokenType::SEMICN;
else if (s == ",")
return frontend::TokenType::COMMA;
else if (s == "(")
return frontend::TokenType::LPARENT;
else if (s == ")")
return frontend::TokenType::RPARENT;
else if (s == "[")
return frontend::TokenType::LBRACK;
else if (s == "]")
return frontend::TokenType::RBRACK;
else if (s == "{")
return frontend::TokenType::LBRACE;
else if (s == "}")
return frontend::TokenType::RBRACE;
else if (s == "!")
return frontend::TokenType::NOT;
else if (s == "<=")
return frontend::TokenType::LEQ;
else if (s == ">=")
return frontend::TokenType::GEQ;
else if (s == "==")
return frontend::TokenType::EQL;
else if (s == "!=")
return frontend::TokenType::NEQ;
else if (s == "&&")
return frontend::TokenType::AND;
else if (s == "||")
return frontend::TokenType::OR;
else // 如果都不是,错误
assert(0 && "invalid operator!");
}
bool isDoubleWidthOperator(std::string s)//判断是不是两字符宽的操作符
{
return s == ">=" || s == "<=" || s == "==" ||
s == "!=" || s == "&&" || s == "||";
}
3、按照DFA来补全bool frontend::DFA::next(char input, Token &buf)
bool frontend::DFA::next(char input, Token &buf)//buf存储当前识别的词法单元(token)信息
{
#ifdef DEBUG_DFA
#include <iostream>
std::cout << "in state [" << toString(cur_state) << "], input = \'" << input << "\', str = " << cur_str << std::endl;
#endif
bool flag = false;//表示当前是否成功识别并返回了一个 token
switch (cur_state)//在头文件DFA类内定义的当前状态
{
case frontend::State::Empty: //空状态
if (isSpace(input)) // 读入一个空白字符
reset(); // 重置状态
else if (isAlpha(input) || input == '_') // 读入一个字母或下划线
{ // 说明可能是标识符
cur_state = frontend::State::Ident; // 转换到Ident状态
cur_str += input; // 并把这个字符存入缓冲区
}
else if (isdigit(input)) // 读入一个数字
{
cur_state = frontend::State::IntLiteral; // 转换到IntLiteral状态
cur_str += input;
}
else if (input == '.') // 读入一个小数点
{
cur_state = frontend::State::FloatLiteral; // 转换到FloatLiteral状态
cur_str += input;
}
else if (isOperator(input)) // 读入一个操作符
{
cur_state = frontend::State::op; // 转换到op状态
cur_str += input;
}
else // 读入其他字符都是非法输入
assert(0 && "invalid input");
break;
case frontend::State::Ident: //标识符状态
if (isSpace(input)) // 读入一个空白字符
{
buf.type = getIdentType(cur_str);
buf.value = cur_str; // 存储当前标识符
reset(); // 重置状态
flag = true;
}
else if (isAlpha(input) || isdigit(input) || input == '_')// 读入一个字母或数字或下划线
{
cur_state = frontend::State::Ident; // 转换到Ident状态
cur_str += input;
}
else if (isOperator(input)) // 读入一个操作符
{
buf.type = getIdentType(cur_str);
buf.value = cur_str;
cur_str = "";
cur_state = frontend::State::op; // 转换到op状态
cur_str += input;
flag = true;
}
else
assert(0 && "invalid input");
break;
case frontend::State::IntLiteral: //整型状态
if (isSpace(input)) // 读入一个空白字符
{
buf.type = frontend::TokenType::INTLTR;
buf.value = cur_str;
reset();
flag = true;
}
else if (isdigit(input) || isAlpha(input)) // 读入一个字母(0d00)或数字
{
cur_state = frontend::State::IntLiteral;
cur_str += input;
}
else if (input == '.') // 读入一个小数点,说明是小数
{
cur_state = frontend::State::FloatLiteral;
cur_str += input;
}
else if (isOperator(input)) // 读入一个操作符
{
buf.type = frontend::TokenType::INTLTR;
buf.value = cur_str;
cur_str = "";
cur_state = frontend::State::op;
cur_str += input;
flag = true;
}
else
assert(0 && "invalid input");
break;
case frontend::State::FloatLiteral: //浮点状态
if (isSpace(input)) // 读入一个空白字符
{
buf.type = frontend::TokenType::FLOATLTR;
buf.value = cur_str;
reset();
flag = true;
}
else if (isdigit(input)) // 读入一个数字
{
cur_state = frontend::State::FloatLiteral;
cur_str += input;
}
else if (isOperator(input)) // 读入一个操作符
{
buf.type = frontend::TokenType::FLOATLTR;
buf.value = cur_str;
cur_str = "";
cur_state = frontend::State::op;
cur_str += input;
flag = true;
}
else
assert(0 && "invalid input");
break;
case frontend::State::op: //操作符状态
if (isSpace(input)) // 读入一个空白字符
{
buf.type = getOpType(cur_str);
buf.value = cur_str;
reset();
flag = true;
}
else if (isAlpha(input) || input == '_') // 读入一个字母或下划线
{
buf.type = getOpType(cur_str);
buf.value = cur_str;
cur_str = "";
cur_state = frontend::State::Ident;
cur_str += input;
flag = true;
}
else if (isdigit(input)) // 读入一个数字
{
buf.type = getOpType(cur_str);
buf.value = cur_str;
cur_str = "";
cur_state = frontend::State::IntLiteral;
cur_str += input;
flag = true;
}
else if (isOperator(input)) // 读入一个操作符
{
if (isDoubleWidthOperator(cur_str + input)) //双字符
cur_str += input;
else
{
buf.type = getOpType(cur_str);
buf.value = cur_str;
cur_str = "";
cur_state = frontend::State::op;
cur_str += input;
flag = true;
}
}
else if (input == '.') // 读入一个小数点
{
buf.type = getOpType(cur_str);
buf.value = cur_str;
cur_str = "";
cur_state = frontend::State::FloatLiteral;
cur_str += input;
flag = true;
}
else
assert(0 && "invalid input");
break;
default:
assert(0 && "invalid state");
break;
}
// #ifdef DEBUG_DFA
// std::cout << "next state is [" << toString(cur_state) << "], next str = " << cur_str << "\t, ret = " << ret << std::endl;
// #endif
return flag;
}
调用
std::vector<frontend::Token> frontend::Scanner::run()
{
std::vector<Token> tokens; // 最后返回的扫描结果
Token tk; // 逐字符扫描的识别符结果
DFA dfa; // 有限自动机
std::string str = preproccess(fin); // fin是scanner读入的文件
str += "\n";
for (char c : str) // 逐字符扫描
{
if (dfa.next(c, tk))
{
tokens.push_back(tk);
#ifdef DEBUG_SCANNER
#include <iostream>
std::cout << "token: " << toString(tk.type) << "\t" << tk.value << std::endl;
#endif
}
}
return tokens;
}
语法分析
语法分析的输入是词法分析输出的token串,输出则是一棵抽象语法树。抽象语法树(abstract syntax tree, AST)是源代码语法结构的一种抽象表示。它以树状的形式表现编程语言的语法结构,树上的每个节点都表示源代码中的一种结构。代码框架中提供了关于抽象语法树每个节点的定义。
抽象语法树
syntax.cpp就是接下来我们要补充的文件
我们这里面采取递归下降法
具体实现的方法如下所示:
-
判断当前index所指的token是否为产生式所要求的
token类型,如果不是则发生了错误,通过assert语句中断。具体是实现了一组matchNode函数,函数返回这一节点下所有可能的token组合。这里给出一个CompUnit的例子:std::unordered_set<frontend::TokenType> Parser::matchCompUnit() { // CompUnit -> (Decl | FuncDef) [CompUnit] return {frontend::TokenType::CONSTTK, frontend::TokenType::INTTK, frontend::TokenType::FLOATTK, frontend::TokenType::VOIDTK}; } -
函数的主体功能就是如果匹配上这样的节点,就开始执行递归。
new一个Term节点并将token内容拷贝到节点中,将该节点加入parent的子节点,Parser的index++。 -
这里还实现了一个
undo函数来进行回溯:void Parser::undo(int _lastIndex, AstNode *_res, int _curChildrenNums) { index = _lastIndex; while (_res->children.size() > _curChildrenNums) _res->children.pop_back(); return; }需要进行回溯的原因就是已经配上了部分
token,但是发现之后的匹配失败了,说明其实不是这种情况,需要回溯到最初的状态跳过这种情况继续匹配下一种情况。所以undo的功能就是恢复开始时token的下标,然后把错误加入的子节点弹出。
列举出可能的文法规则
注:这里面的规则是消除了左递归了的
如原本加法
AddExp -> AddExp '+' MulExp | AddExp '-' MulExp | MulExp
是会出现左递归的情况
而这里则采用循环的形式
AddExp -> MulExp { ('+' | '-') MulExp }
- 编译单元 (CompUnit)
CompUnit -> (Decl | FuncDef) [CompUnit]
- 一个编译单元由一个声明(Decl)或函数定义(FuncDef)组成,后面可以跟另一个编译单元(递归定义)
- 表示一个程序可以由多个声明和函数定义组成
- 声明 (Decl)
Decl -> ConstDecl | VarDecl
- 声明可以是常量声明或变量声明
- 常量声明 (ConstDecl)
ConstDecl -> 'const' BType ConstDef { ',' ConstDef } ';'
- 以关键字
const开头 - 后跟基本类型(BType)
- 然后是一个或多个常量定义(ConstDef),用逗号分隔
- 最后以分号结束
- 基本类型 (BType)
BType -> 'int' | 'float'
- 基本类型可以是
int或float
- 常量定义 (ConstDef)
ConstDef -> Ident { '[' ConstExp ']' } '=' ConstInitVal
- 以标识符(Ident)开头
- 可以有多个数组维度(用方括号和常量表达式ConstExp表示)
- 必须有等号和常量初值(ConstInitVal)
- 常量初值 (ConstInitVal)
ConstInitVal -> ConstExp | '{' [ ConstInitVal { ',' ConstInitVal } ] '}'
- 可以是单个常量表达式(ConstExp)
- 或者用花括号括起来的多个常量初值,用逗号分隔(用于数组初始化)
- 变量声明 (VarDecl)
VarDecl -> BType VarDef { ',' VarDef } ';'
- 以基本类型(BType)开头
- 然后是一个或多个变量定义(VarDef),用逗号分隔
- 最后以分号结束
- 变量定义 (VarDef)
VarDef -> Ident { '[' ConstExp ']' } [ '=' InitVal ]
- 以标识符(Ident)开头
- 可以有多个数组维度(用方括号和常量表达式ConstExp表示)
- 可以选择性地用等号和初值(InitVal)初始化
- 变量初值 (InitVal)
InitVal -> Exp | '{' [ InitVal { ',' InitVal } ] '}'
- 可以是单个表达式(Exp)
- 或者用花括号括起来的多个变量初值,用逗号分隔(用于数组初始化)
- 函数定义 (FuncDef)
FuncDef -> FuncType Ident '(' [FuncFParams] ')' Block
- 以函数类型(FuncType)开头
- 然后是函数名(Ident)
- 接着是参数列表(可选),用括号括起来
- 最后是函数体(Block)
- 函数类型 (FuncType)
FuncType -> 'void' | 'int' | 'float'
- 函数返回类型可以是
void、int或float
- 函数形参 (FuncFParam)
FuncFParam -> BType Ident [ '[' ']' { '[' Exp ']' } ]
- 以基本类型(BType)开头
- 然后是参数名(Ident)
- 对于数组参数,可以有多个维度(用方括号表示)
- 函数形参表 (FuncFParams)
FuncFParams -> FuncFParam { ',' FuncFParam }
- 由一个或多个函数形参(FuncFParam)组成,用逗号分隔
- 语句块 (Block)
Block -> '{' { BlockItem } '}'
- 用花括号括起来
- 包含零个或多个语句块项(BlockItem)
- 语句块项 (BlockItem)
BlockItem -> Decl | Stmt
- 可以是声明(Decl)或语句(Stmt)
- 语句 (Stmt)
Stmt -> LVal '=' Exp ';' | Block | 'if' '(' Cond ')' Stmt [ 'else' Stmt ] | 'while' '(' Cond ')' Stmt | 'break' ';' | 'continue' ';' | 'return' [Exp] ';' | [Exp] ';'
- 多种语句类型:
- 赋值语句:左值=表达式;
- 语句块
- if语句:可以有可选的else部分
- while循环
- break语句
- continue语句
- return语句:可以带或不带返回值
- 表达式语句(可以只有分号)
- 表达式 (Exp)
Exp -> AddExp
- 表达式最终归结为加法表达式(AddExp)
- 条件表达式 (Cond)
Cond -> LOrExp
- 条件表达式归结为逻辑或表达式(LOrExp)
- 左值表达式 (LVal)
LVal -> Ident { '[' Exp ']' }
- 左值是一个标识符,可以有多个数组索引(用方括号和表达式表示)
- 数值 (Number)
Number -> IntConst | floatConst
- 数值可以是整型常量或浮点型常量
- 基本表达式 (PrimaryExp)
PrimaryExp -> '(' Exp ')' | LVal | Number
- 可以是括号括起来的表达式
- 或左值表达式
- 或数值
- 一元表达式 (UnaryExp)
UnaryExp -> PrimaryExp | Ident '(' [FuncRParams] ')' | UnaryOp UnaryExp
- 可以是基本表达式
- 或函数调用(标识符后跟括号和可选的实际参数)
- 或带单目运算符的一元表达式
- 单目运算符 (UnaryOp)
UnaryOp -> '+' | '-' | '!'
- 可以是正号、负号或逻辑非
- 函数实参表 (FuncRParams)
FuncRParams -> Exp { ',' Exp }
- 由一个或多个表达式组成,用逗号分隔
- 乘除模表达式 (MulExp)
MulExp -> UnaryExp { ( '*' | '/' | '%' ) UnaryExp }
- 一元表达式之间可以有乘、除或取模运算
- 加减表达式 (AddExp)
AddExp -> MulExp { ( '+' | '-' ) MulExp }
- 乘除模表达式之间可以有加或减运算
- 关系表达式 (RelExp)
RelExp -> AddExp { ( '<' | '>' | '<=' | '>=' ) AddExp }
- 加减表达式之间可以有关系比较运算
- 相等性表达式 (EqExp)
EqExp -> RelExp { ( '==' | '!=' ) RelExp }
- 关系表达式之间可以有相等或不等比较
- 逻辑与表达式 (LAndExp)
LAndExp -> EqExp [ '&&' LAndExp ]
- 相等性表达式之间可以有逻辑与运算
- 逻辑或表达式 (LOrExp)
LOrExp -> LAndExp [ '||' LOrExp ]
- 逻辑与表达式之间可以有逻辑或运算
- 常量表达式 (ConstExp)
ConstExp -> AddExp
- 常量表达式归结为加法表达式(AddExp),但在编译时必须能计算出常数值
对上面文法的解析实现
注:
#include <set>
头文件声明文法相关函数
// 添加相关函数的声明,parseCompUnit函数创建根节点,直接对接get_abstract_syntax_tree函数,返回值为*AstNode
// 其余递归下降法函数返回值都是bool类型
CompUnit *parseCompUnit(AstNode *root);
bool parseDecl(AstNode *root);
bool parseConstDecl(AstNode *root);
bool parseBType(AstNode *root);
bool parseConstDef(AstNode *root);
bool parseConstInitVal(AstNode *root);
bool parseVarDecl(AstNode *root);
bool parseVarDef(AstNode *root);
bool parseInitVal(AstNode *root);
bool parseFuncDef(AstNode *root);
bool parseFuncType(AstNode *root);
bool parseFuncFParam(AstNode *root);
bool parseFuncFParams(AstNode *root);
bool parseBlock(AstNode *root);
bool parseBlockItem(AstNode *root);
bool parseStmt(AstNode *root);
bool parseExp(AstNode *root);
bool parseCond(AstNode *root);
bool parseLVal(AstNode *root);
bool parseNumber(AstNode *root);
bool parsePrimaryExp(AstNode *root);
bool parseUnaryExp(AstNode *root);
bool parseUnaryOp(AstNode *root);
bool parseFuncRParams(AstNode *root);
bool parseMulExp(AstNode *root);
bool parseAddExp(AstNode *root);
bool parseRelExp(AstNode *root);
bool parseEqExp(AstNode *root);
bool parseLAndExp(AstNode *root);
bool parseLOrExp(AstNode *root);
bool parseConstExp(AstNode *root);
// 分支判断函数,判断是否存在这一语法分支
// 返回的是相应语法规则的First 集
std::set<frontend::TokenType> matchCompUnit();
std::set<frontend::TokenType> matchDecl();
std::set<frontend::TokenType> matchConstDecl();
std::set<frontend::TokenType> matchBType();
std::set<frontend::TokenType> matchConstDef();
std::set<frontend::TokenType> matchConstInitVal();
std::set<frontend::TokenType> matchVarDecl();
std::set<frontend::TokenType> matchVarDef();
std::set<frontend::TokenType> matchInitVal();
std::set<frontend::TokenType> matchFuncDef();
std::set<frontend::TokenType> matchFuncType();
std::set<frontend::TokenType> matchFuncFParam();
std::set<frontend::TokenType> matchFuncFParams();
std::set<frontend::TokenType> matchBlock();
std::set<frontend::TokenType> matchBlockItem();
std::set<frontend::TokenType> matchStmt();
std::set<frontend::TokenType> matchExp();
std::set<frontend::TokenType> matchCond();
std::set<frontend::TokenType> matchLVal();
std::set<frontend::TokenType> matchNumber();
std::set<frontend::TokenType> matchPrimaryExp();
std::set<frontend::TokenType> matchUnaryExp();
std::set<frontend::TokenType> matchUnaryOp();
std::set<frontend::TokenType> matchFuncRParams();
std::set<frontend::TokenType> matchMulExp();
std::set<frontend::TokenType> matchAddExp();
std::set<frontend::TokenType> matchRelExp();
std::set<frontend::TokenType> matchEqExp();
std::set<frontend::TokenType> matchLAndExp();
std::set<frontend::TokenType> matchLOrExp();
std::set<frontend::TokenType> matchConstExp();
语法预测函数(First集)
- 编译单元 (CompUnit)
std::set<frontend::TokenType> Parser::matchCompUnit()
{ // CompUnit -> (Decl | FuncDef) [CompUnit]
return {
frontend::TokenType::CONSTTK,
frontend::TokenType::INTTK,
frontend::TokenType::FLOATTK,
frontend::TokenType::VOIDTK};
}
- 声明 (Decl)
std::set<frontend::TokenType> Parser::matchDecl() {
// Decl -> ConstDecl | VarDecl
return {frontend::TokenType::CONSTTK, // ConstDecl 的起始 Token
frontend::TokenType::INTTK, // VarDecl 的起始 Token (BType)
frontend::TokenType::FLOATTK}; // VarDecl 的起始 Token (BType)
}
- 常量声明 (ConstDecl)
std::set<frontend::TokenType> Parser::matchConstDecl() {
// ConstDecl -> 'const' BType ConstDef { ',' ConstDef } ';'
return {frontend::TokenType::CONSTTK}; // 必须以 'const' 开头
}
- 基本类型 (BType)
std::set<frontend::TokenType> Parser::matchBType()
{ // BType -> 'int' | 'float'
return {frontend::TokenType::INTTK, frontend::TokenType::FLOATTK};
}
- 常量定义 (ConstDef)
std::set<frontend::TokenType> Parser::matchConstDef()
{ // ConstDef -> Ident { '[' ConstExp ']' } '=' ConstInitVal
return {frontend::TokenType::IDENFR};
}
- 常量初值 (ConstInitVal)
std::set<frontend::TokenType> Parser::matchConstInitVal()
{
// 返回可能出现在常量初始值开头的所有Token类型集合
return {
frontend::TokenType::IDENFR, // 标识符(可能是常量名)
frontend::TokenType::INTLTR, // 整型字面量
frontend::TokenType::FLOATLTR, // 浮点字面量
frontend::TokenType::LPARENT, // 左括号'(' (可能用于表达式分组)
frontend::TokenType::PLUS, // 加号'+' (正号)
frontend::TokenType::MINU, // 减号'-' (负号)
frontend::TokenType::NOT, // 逻辑非'!'
frontend::TokenType::LBRACE // 左花括号'{' (表示初始化列表开始)
};
}
- 变量声明 (VarDecl)
std::set<frontend::TokenType> Parser::matchVarDecl() {
// VarDecl -> BType VarDef { ',' VarDef } ';'
return {frontend::TokenType::INTTK, // BType 可以是 'int'
frontend::TokenType::FLOATTK}; // BType 可以是 'float'
}
- 变量定义 (VarDef)
std::set<frontend::TokenType> Parser::matchVarDef() {
// VarDef -> Ident { '[' ConstExp ']' } [ '=' InitVal ]
return {frontend::TokenType::IDENFR}; // 标识符
}
- 变量初值 (InitVal)
std::set<frontend::TokenType> Parser::matchInitVal() {
// InitVal -> Exp | '{' [ InitVal { ',' InitVal } ] '}'
return {frontend::TokenType::IDENFR, // 标识符(可能是常量名)
frontend::TokenType::INTLTR, // 整型字面量(如 42)
frontend::TokenType::FLOATLTR, // 浮点字面量(如 3.14)
frontend::TokenType::LPARENT, // '('(可能是表达式)
frontend::TokenType::PLUS, // '+'(一元正号)
frontend::TokenType::MINU, // '-'(一元负号)
frontend::TokenType::NOT, // '!'(逻辑非)
frontend::TokenType::LBRACE}; // '{'(初始化列表)
}
- 函数定义 (FuncDef)
std::set<frontend::TokenType> Parser::matchFuncDef()
{ // FuncDef -> FuncType Ident '(' [FuncFParams] ')' Block
return {
frontend::TokenType::VOIDTK,
frontend::TokenType::INTTK,
frontend::TokenType::FLOATTK};
}
- 函数类型 (FuncType)
std::set<frontend::TokenType> Parser::matchFuncType()
{ // FuncType -> 'void' | 'int' | 'float'
return {
frontend::TokenType::VOIDTK,
frontend::TokenType::INTTK,
frontend::TokenType::FLOATTK};
}
- 函数形参 (FuncFParam)
std::set<frontend::TokenType> Parser::matchFuncFParam()
{ // FuncFParam -> BType Ident [ '[' ']' { '[' Exp ']' } ]
return {frontend::TokenType::INTTK, frontend::TokenType::FLOATTK};
}
- 函数形参表 (FuncFParams)
std::set<frontend::TokenType> Parser::matchFuncFParams()
{ // FuncFParams -> FuncFParam { ',' FuncFParam }
return {frontend::TokenType::INTTK, frontend::TokenType::FLOATTK};
}
- 语句块 (Block)
std::set<frontend::TokenType> Parser::matchBlock() {
// Block -> '{' { BlockItem } '}'
return {frontend::TokenType::LBRACE}; // '{'
}
- 语句块项 (BlockItem)
std::set<frontend::TokenType> Parser::matchBlockItem() {
// BlockItem -> Decl | Stmt
return {
// Decl 的 First 集
frontend::TokenType::CONSTTK, // 'const' (ConstDecl)
frontend::TokenType::INTTK, // 'int' (VarDecl)
frontend::TokenType::FLOATTK, // 'float' (VarDecl)
// Stmt 的 First 集
frontend::TokenType::IDENFR, // 标识符 (赋值语句或表达式语句)
frontend::TokenType::IFTK, // 'if'
frontend::TokenType::WHILETK, // 'while'
frontend::TokenType::BREAKTK, // 'break'
frontend::TokenType::CONTINUETK, // 'continue'
frontend::TokenType::RETURNTK, // 'return'
frontend::TokenType::SEMICN, // ';' (空语句)
frontend::TokenType::INTLTR, // 整数字面量 (表达式)
frontend::TokenType::FLOATLTR, // 浮点字面量 (表达式)
frontend::TokenType::LPARENT, // '(' (表达式)
frontend::TokenType::PLUS, // '+' (一元表达式)
frontend::TokenType::MINU, // '-' (一元表达式)
frontend::TokenType::NOT, // '!' (一元表达式)
frontend::TokenType::LBRACE // '{' (嵌套 Block)
};
}
- 语句 (Stmt)
std::set<frontend::TokenType> Parser::matchStmt()
{ // Stmt -> LVal '=' Exp ';' | Block | 'if' '(' Cond ')' Stmt [ 'else' Stmt ] | 'while' '(' Cond ')' Stmt | 'break' ';' | 'continue' ';' | 'return' [Exp] ';' | [Exp] ';'
return {
frontend::TokenType::IDENFR, // 标识符 (赋值语句或表达式语句)
frontend::TokenType::IFTK, // 'if'
frontend::TokenType::WHILETK, // 'while'
frontend::TokenType::BREAKTK, // 'break'
frontend::TokenType::CONTINUETK, // 'continue'
frontend::TokenType::RETURNTK, // 'return'
frontend::TokenType::SEMICN, // ';' (空语句)
frontend::TokenType::INTLTR, // 整数字面量 (表达式)
frontend::TokenType::FLOATLTR, // 浮点字面量 (表达式)
frontend::TokenType::LPARENT, // '(' (表达式)
frontend::TokenType::PLUS, // '+' (一元表达式)
frontend::TokenType::MINU, // '-' (一元表达式)
frontend::TokenType::NOT, // '!' (一元表达式)
frontend::TokenType::LBRACE // '{' (嵌套 Block)
};
}
- 表达式 (Exp)
std::set<frontend::TokenType> Parser::matchExp() {
// Exp -> AddExp
return {
frontend::TokenType::IDENFR, // 标识符 (变量/函数调用)
frontend::TokenType::INTLTR, // 整数字面量 (如 42)
frontend::TokenType::FLOATLTR, // 浮点字面量 (如 3.14)
frontend::TokenType::LPARENT, // '(' (括号表达式)
frontend::TokenType::PLUS, // '+' (一元正号)
frontend::TokenType::MINU, // '-' (一元负号)
frontend::TokenType::NOT // '!' (逻辑非)
};
}
- 条件表达式 (Cond)
std::set<frontend::TokenType> Parser::matchCond() {
// Cond -> LOrExp
return {
frontend::TokenType::IDENFR, // 与 Exp 相同
frontend::TokenType::INTLTR,
frontend::TokenType::FLOATLTR,
frontend::TokenType::LPARENT,
frontend::TokenType::PLUS,
frontend::TokenType::MINU,
frontend::TokenType::NOT
};
}
- 左值表达式 (LVal)
std::set<frontend::TokenType> Parser::matchLVal() {
// LVal -> Ident { '[' Exp ']' }
return {frontend::TokenType::IDENFR}; // 必须为标识符
}
- 数值 (Number)
std::set<frontend::TokenType> Parser::matchNumber()
{ // Number -> IntConst | floatConst
return {frontend::TokenType::INTLTR, frontend::TokenType::FLOATLTR};
}
- 基本表达式 (PrimaryExp)
std::set<frontend::TokenType> Parser::matchPrimaryExp()
{ // PrimaryExp -> '(' Exp ')' | LVal | Number
return {
frontend::TokenType::IDENFR,
frontend::TokenType::INTLTR,
frontend::TokenType::FLOATLTR,
frontend::TokenType::LPARENT};
}
- 一元表达式 (UnaryExp)
std::set<frontend::TokenType> Parser::matchUnaryExp()
{ // UnaryExp -> PrimaryExp | Ident '(' [FuncRParams] ')' | UnaryOp UnaryExp
return {
frontend::TokenType::IDENFR,
frontend::TokenType::INTLTR,
frontend::TokenType::FLOATLTR,
frontend::TokenType::LPARENT,
frontend::TokenType::PLUS,
frontend::TokenType::MINU,
frontend::TokenType::NOT};
}
- 单目运算符 (UnaryOp)
std::set<frontend::TokenType> Parser::matchUnaryOp()
{ // UnaryOp -> '+' | '-' | '!'
return {
frontend::TokenType::PLUS,
frontend::TokenType::MINU,
frontend::TokenType::NOT};
}
- 函数实参表 (FuncRParams)
std::set<frontend::TokenType> Parser::matchFuncRParams() {
// FuncRParams -> Exp { ',' Exp }
return {
frontend::TokenType::IDENFR, // 标识符(变量名或函数调用)
frontend::TokenType::INTLTR, // 整数字面量(如 42)
frontend::TokenType::FLOATLTR, // 浮点字面量(如 3.14)
frontend::TokenType::LPARENT, // '('(括号表达式)
frontend::TokenType::PLUS, // '+'(一元正号)
frontend::TokenType::MINU, // '-'(一元负号)
frontend::TokenType::NOT // '!'(逻辑非)
};
}
为什么不是左括号 (:
左括号 ( 属于函数调用语法的一部分(如 func(...)),不是实参表本身的组成部分
在解析器看到 ( 时,已经确定要解析函数调用,然后才开始解析参数列表
因此 FuncRParams 的 First 集应该是参数表达式(Exp)的 First 集
- 乘除模表达式 (MulExp)
std::set<frontend::TokenType> Parser::matchMulExp()
{ // MulExp -> UnaryExp { ( '*' | '/' | '%' ) UnaryExp }
return {
frontend::TokenType::IDENFR,
frontend::TokenType::INTLTR,
frontend::TokenType::FLOATLTR,
frontend::TokenType::LPARENT,
frontend::TokenType::PLUS,
frontend::TokenType::MINU,
frontend::TokenType::NOT};
}
- 加减表达式 (AddExp)
std::set<frontend::TokenType> Parser::matchAddExp()
{ // AddExp -> MulExp { ( '+' | '-' ) MulExp }
return {
frontend::TokenType::IDENFR,
frontend::TokenType::INTLTR,
frontend::TokenType::FLOATLTR,
frontend::TokenType::LPARENT,
frontend::TokenType::PLUS,
frontend::TokenType::MINU,
frontend::TokenType::NOT};
}
- 关系表达式 (RelExp)
std::set<frontend::TokenType> Parser::matchRelExp()
{ // RelExp -> AddExp { ( '<' | '>' | '<=' | '>=' ) AddExp }
return {
frontend::TokenType::IDENFR,
frontend::TokenType::INTLTR,
frontend::TokenType::FLOATLTR,
frontend::TokenType::LPARENT,
frontend::TokenType::PLUS,
frontend::TokenType::MINU,
frontend::TokenType::NOT};
}
- 相等性表达式 (EqExp)
std::set<frontend::TokenType> Parser::matchEqExp()
{ // EqExp -> RelExp { ( '==' | '!=' ) RelExp }
return {
frontend::TokenType::IDENFR,
frontend::TokenType::INTLTR,
frontend::TokenType::FLOATLTR,
frontend::TokenType::LPARENT,
frontend::TokenType::PLUS,
frontend::TokenType::MINU,
frontend::TokenType::NOT};
}
- 逻辑与表达式 (LAndExp)
std::set<frontend::TokenType> Parser::matchLAndExp()
{ // LAndExp -> EqExp [ '&&' LAndExp ]
return {
frontend::TokenType::IDENFR,
frontend::TokenType::INTLTR,
frontend::TokenType::FLOATLTR,
frontend::TokenType::LPARENT,
frontend::TokenType::PLUS,
frontend::TokenType::MINU,
frontend::TokenType::NOT};
}
- 逻辑或表达式 (LOrExp)
std::set<frontend::TokenType> Parser::matchLOrExp()
{ // LOrExp -> LAndExp [ '||' LOrExp ]
return {
frontend::TokenType::IDENFR,
frontend::TokenType::INTLTR,
frontend::TokenType::FLOATLTR,
frontend::TokenType::LPARENT,
frontend::TokenType::PLUS,
frontend::TokenType::MINU,
frontend::TokenType::NOT};
}
- 常量表达式 (ConstExp)
std::set<frontend::TokenType> Parser::matchConstExp()
{ // ConstExp -> AddExp
return {
frontend::TokenType::IDENFR,
frontend::TokenType::INTLTR,
frontend::TokenType::FLOATLTR,
frontend::TokenType::LPARENT,
frontend::TokenType::PLUS,
frontend::TokenType::MINU,
frontend::TokenType::NOT};
}
文法解析
#define saveChildrenNum int curChildrenNums = res->children.size()
#define saveIndex int lastIndex = index
void Parser::undo(int _lastIndex, AstNode *_res, int _curChildrenNums)
{
index = _lastIndex;
while (_res->children.size() > _curChildrenNums)
_res->children.pop_back();
return;
}
整体流程:
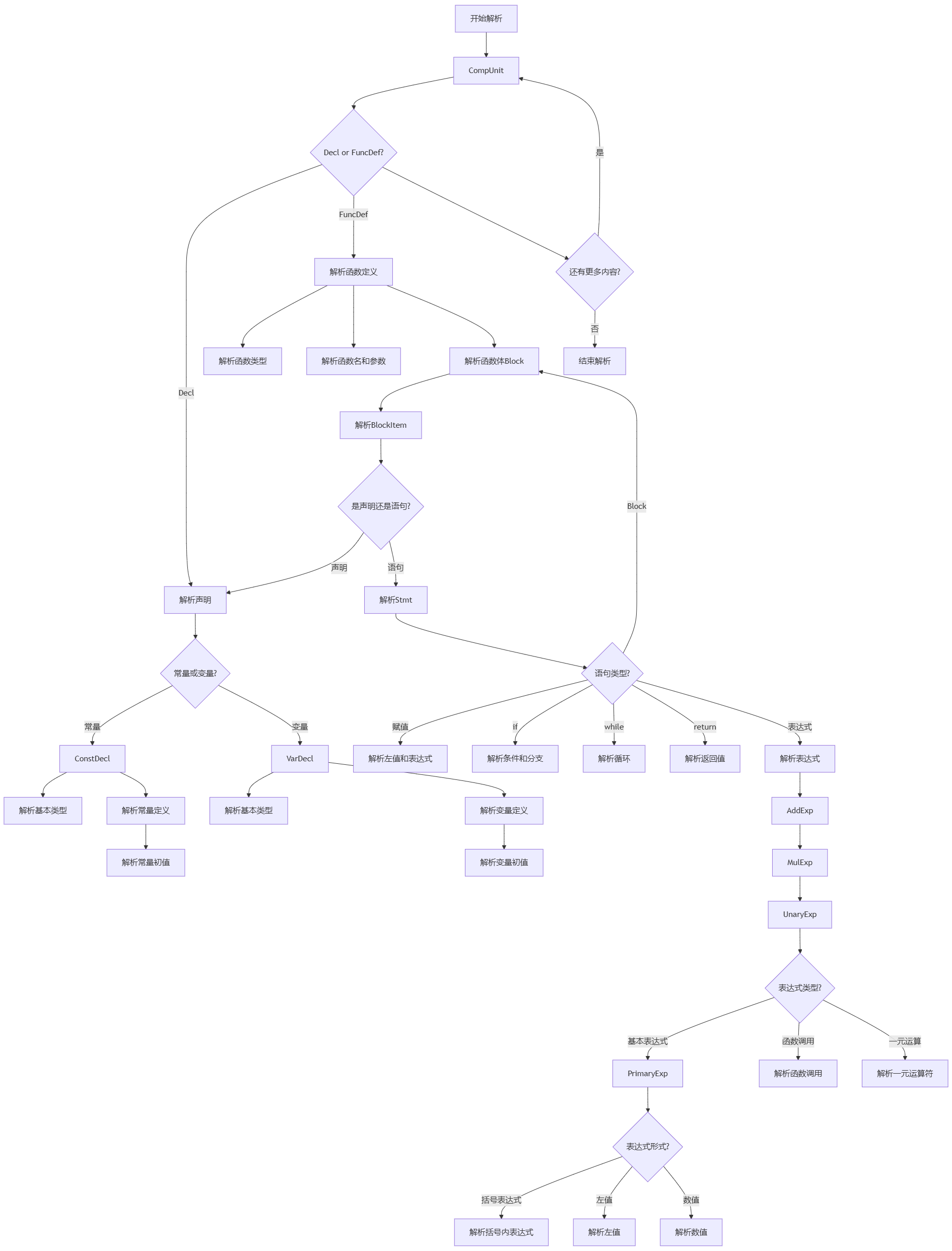
每个函数对应语法中的一个非终结符
- 编译单元 (CompUnit)
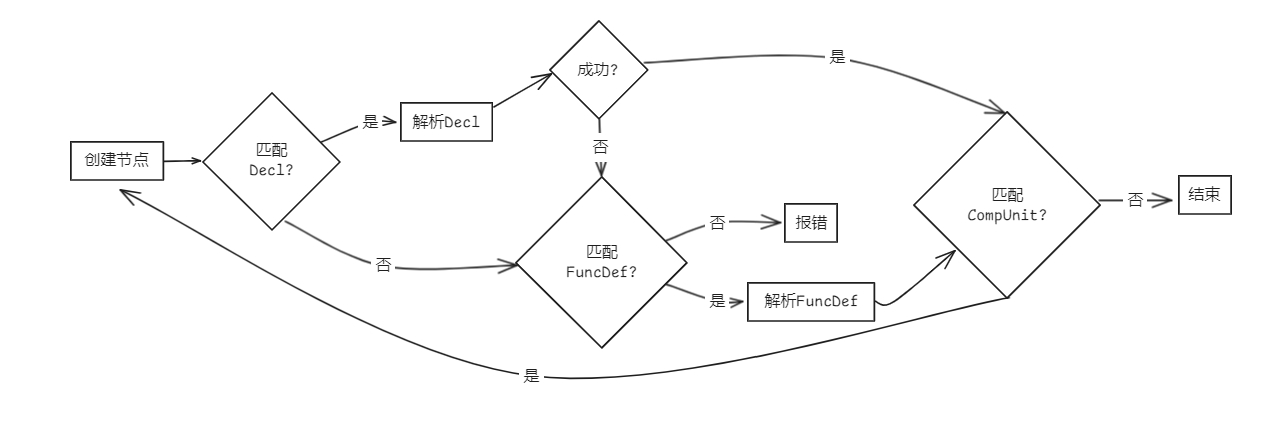
frontend::CompUnit *Parser::parseCompUnit(AstNode *root)
{
CompUnit *res = new CompUnit(root); // 构造根节点
bool isDecl = false; // 标记Decl分支
bool isFuncDef = false; // 标记FuncDef分支
saveIndex; // 记录当前index
saveChildrenNum; // 记录进入分支前的children数量
if (matchDecl().count(token_stream[index].type)) // 匹配Decl
{
isDecl = parseDecl(res);
if (!isDecl)
undo(lastIndex, res, curChildrenNums);
}
if (!isDecl && matchFuncDef().count(token_stream[index].type)) // 匹配FuncDef
isFuncDef = parseFuncDef(res);
if (!isDecl && !isFuncDef) // 两个分支都不匹配报错
assert(0 && "error in parseCompUnit");
if (matchCompUnit().count(token_stream[index].type)) // 匹配CompUnit
parseCompUnit(res);
return res;
}
- 声明 (Decl)
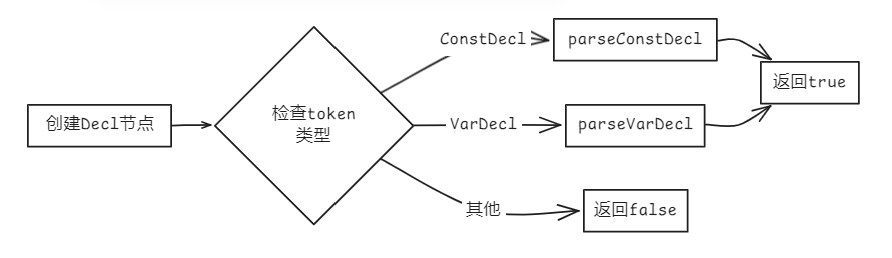
bool Parser::parseDecl(AstNode *root)
{
Decl *res = new Decl(root);
bool isConstDecl = false;
bool isVarDecl = false;
if (matchConstDecl().count(token_stream[index].type)) // 匹配ConstDecl
isConstDecl = parseConstDecl(res);
else if (matchVarDecl().count(token_stream[index].type)) // 匹配VarDecl
isVarDecl = parseVarDecl(res);
if (!isConstDecl && !isVarDecl)
return false;
return true;
}
- 常量声明 (ConstDecl)
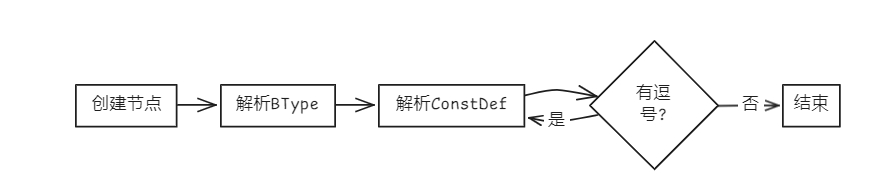
bool Parser::parseConstDecl(AstNode *root)
{
ConstDecl *res = new ConstDecl(root);
new Term(token_stream[index++], res);
parseBType(res); // 匹配BType
parseConstDef(res); // 匹配ConstDef
while (token_stream[index].type == frontend::TokenType::COMMA) // 匹配{ ',' ConstDef }
{
new Term(token_stream[index++], res);
parseConstDef(res);
}
new Term(token_stream[index++], res);
return true;
}
- 基本类型 (BType)
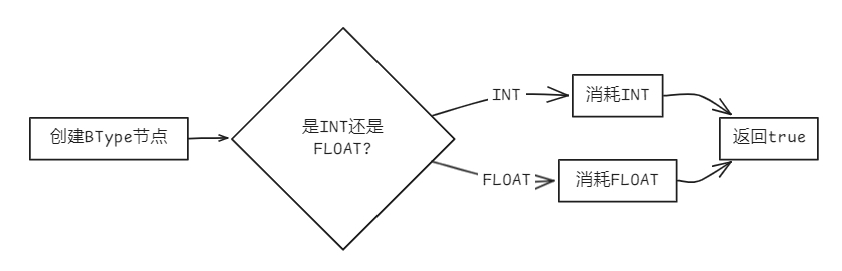
bool Parser::parseBType(AstNode *root)
{
BType *res = new BType(root);
if (token_stream[index].type == frontend::TokenType::INTTK) // 匹配'int'
new Term(token_stream[index++], res);
else if (token_stream[index].type == frontend::TokenType::FLOATTK) // 匹配'float'
new Term(token_stream[index++], res);
return true;
}
- 常量定义 (ConstDef)
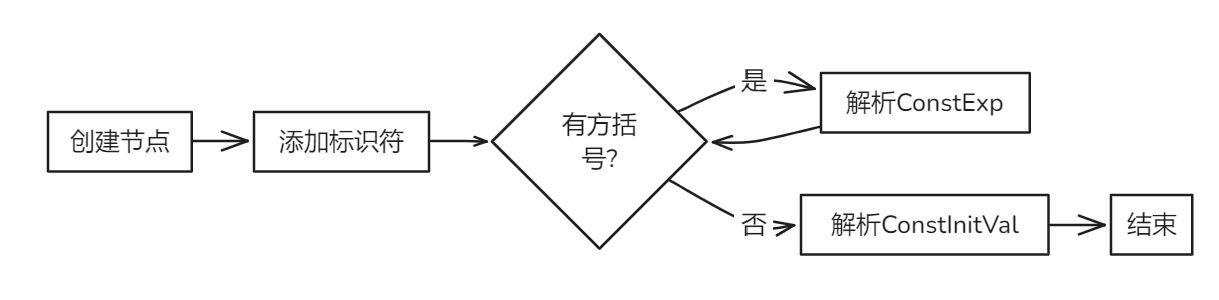
bool Parser::parseConstDef(AstNode *root)
{
ConstDef *res = new ConstDef(root);
new Term(token_stream[index++], res);
while (token_stream[index].type == frontend::TokenType::LBRACK) // 匹配{ '[' ConstExp ']' }
{
new Term(token_stream[index++], res);
parseConstExp(res);
new Term(token_stream[index++], res);
}
new Term(token_stream[index++], res);
parseConstInitVal(res); // 匹配ConstInitVal
return true;
}
- 常量初值 (ConstInitVal)
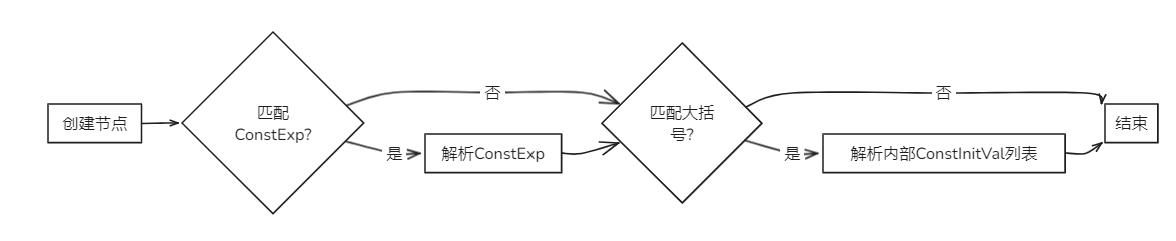
bool Parser::parseConstInitVal(AstNode *root)
{
ConstInitVal *res = new ConstInitVal(root);
if (matchConstExp().count(token_stream[index].type)) // 匹配ConstExp
parseConstExp(res);
if (token_stream[index].type == frontend::TokenType::LBRACE) // 匹配'{' [ ConstInitVal { ',' ConstInitVal } ] '}'
{
new Term(token_stream[index++], res);
if (matchConstInitVal().count(token_stream[index].type))
{
parseConstInitVal(res);
while (token_stream[index].type == frontend::TokenType::COMMA)
{
new Term(token_stream[index++], res);
parseConstInitVal(res);
}
}
new Term(token_stream[index++], res);
}
return true;
}
- 变量声明 (VarDecl)

bool Parser::parseVarDecl(AstNode *root)
{
VarDecl *res = new VarDecl(root);
parseBType(res); // 匹配BType
parseVarDef(res); // 匹配VarDef
while (token_stream[index].type == frontend::TokenType::COMMA) // 匹配{ ',' VarDef }
{
new Term(token_stream[index++], res);
parseVarDef(res);
}
if (token_stream[index].type != frontend::TokenType::SEMICN) // 匹配';'
return false;
new Term(token_stream[index++], res);
return true;
}
- 变量定义 (VarDef)
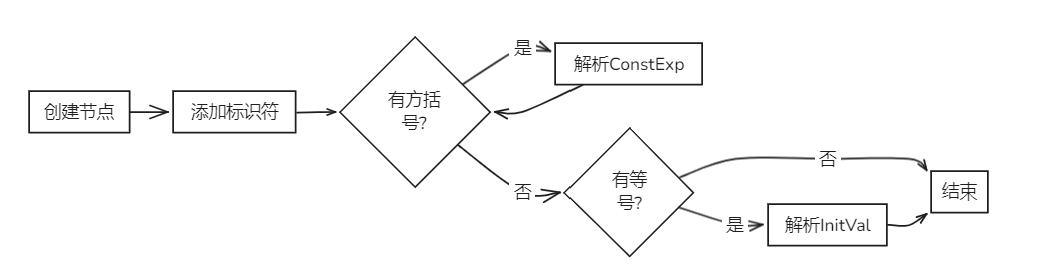
bool Parser::parseVarDef(AstNode *root)
{
VarDef *res = new VarDef(root);
new Term(token_stream[index++], res);
while (token_stream[index].type == frontend::TokenType::LBRACK) // 匹配{ '[' ConstExp ']' }
{
new Term(token_stream[index++], res);
parseConstExp(res);
new Term(token_stream[index++], res);
}
if (token_stream[index].type == frontend::TokenType::ASSIGN) // 匹配[ '=' InitVal ]
{
new Term(token_stream[index++], res);
parseInitVal(res);
}
return true;
}
- 变量初值 (InitVal)

bool Parser::parseInitVal(AstNode *root)
{
InitVal *res = new InitVal(root);
if (matchExp().count(token_stream[index].type)) // 匹配Exp
parseExp(res);
if (token_stream[index].type == frontend::TokenType::LBRACE) // 匹配'{' [ InitVal { ',' InitVal } ] '}'
{
new Term(token_stream[index++], res);
if (matchInitVal().count(token_stream[index].type))
{
parseInitVal(res);
while (token_stream[index].type == frontend::TokenType::COMMA)
{
new Term(token_stream[index++], res);
parseInitVal(res);
}
}
new Term(token_stream[index++], res);
}
return true;
}
- 函数定义 (FuncDef)

bool Parser::parseFuncDef(AstNode *root)
{
FuncDef *res = new FuncDef(root);
parseFuncType(res); // 匹配FuncType
new Term(token_stream[index++], res);
new Term(token_stream[index++], res);
if (matchFuncFParams().count(token_stream[index].type)) // 匹配[FuncFParams]
parseFuncFParams(res);
new Term(token_stream[index++], res);
parseBlock(res); // 匹配Block
return true;
}
- 函数类型 (FuncType)
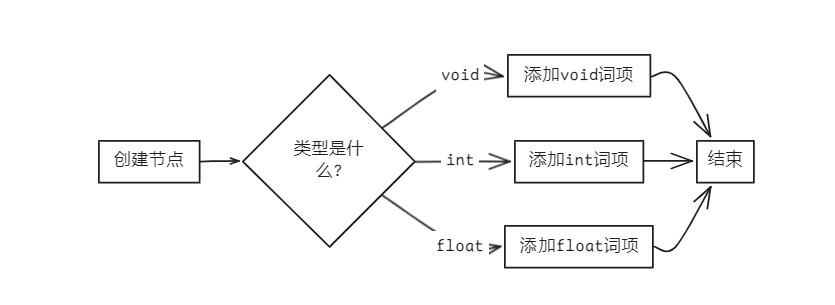
bool Parser::parseFuncType(AstNode *root)
{
FuncType *res = new FuncType(root);
if (token_stream[index].type == frontend::TokenType::VOIDTK)
new Term(token_stream[index++], res);
else if (token_stream[index].type == frontend::TokenType::INTTK)
new Term(token_stream[index++], res);
else if (token_stream[index].type == frontend::TokenType::FLOATTK)
new Term(token_stream[index++], res);
return true;
}
- 函数形参 (FuncFParam)
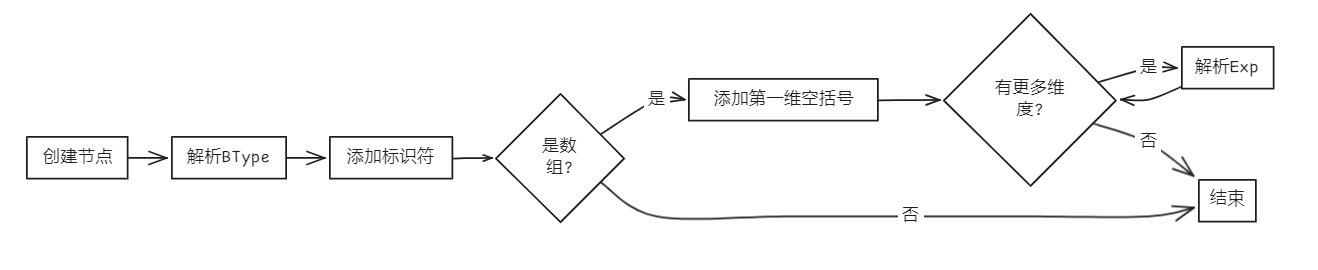
bool Parser::parseFuncFParam(AstNode *root)
{
FuncFParam *res = new FuncFParam(root);
parseBType(res); // 匹配BType
new Term(token_stream[index++], res);
if (token_stream[index].type == frontend::TokenType::LBRACK) // 匹配[ '[' ']' { '[' Exp ']' } ]
{
new Term(token_stream[index++], res);
new Term(token_stream[index++], res);
while (token_stream[index].type == frontend::TokenType::LBRACK)
{
new Term(token_stream[index++], res);
parseExp(res);
new Term(token_stream[index++], res);
}
}
return true;
}
- 函数形参表 (FuncFParams)
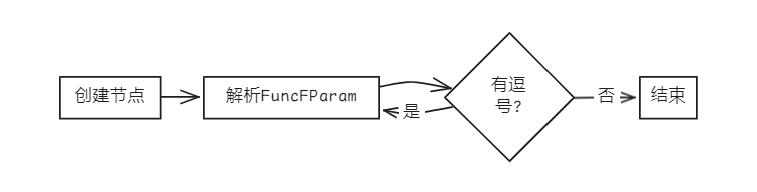
bool Parser::parseFuncFParams(AstNode *root)
{
FuncFParams *res = new FuncFParams(root);
parseFuncFParam(res); // 匹配FuncFParam
while (token_stream[index].type == frontend::TokenType::COMMA) // 匹配{ ',' FuncFParam }
{
new Term(token_stream[index++], res);
parseFuncFParam(res);
}
return true;
}
- 语句块 (Block)
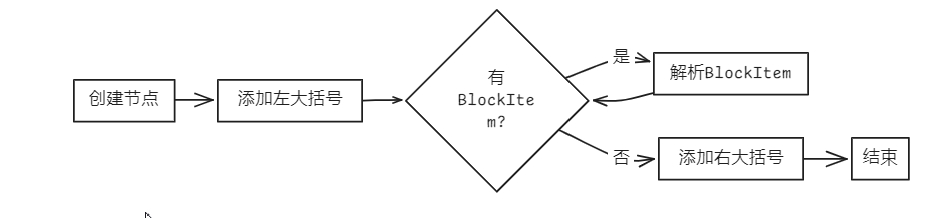
bool Parser::parseBlock(AstNode *root)
{
Block *res = new Block(root);
new Term(token_stream[index++], res);
while (matchBlockItem().count(token_stream[index].type)) // 匹配{ BlockItem }
parseBlockItem(res);
new Term(token_stream[index++], res);
return true;
}
- 语句块项 (BlockItem)
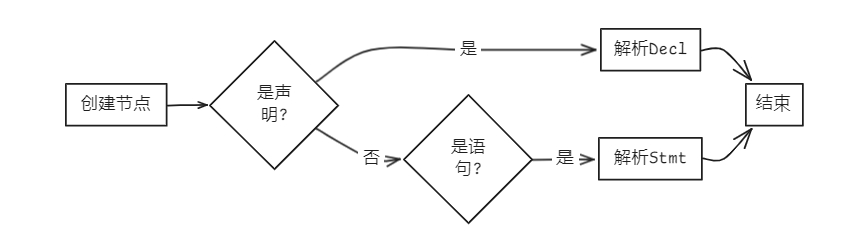
bool Parser::parseBlockItem(AstNode *root)
{
BlockItem *res = new BlockItem(root);
if (matchDecl().count(token_stream[index].type)) // 匹配Decl
parseDecl(res);
else if (matchStmt().count(token_stream[index].type)) // 匹配Stmt
parseStmt(res);
return true;
}
- 语句 (Stmt)
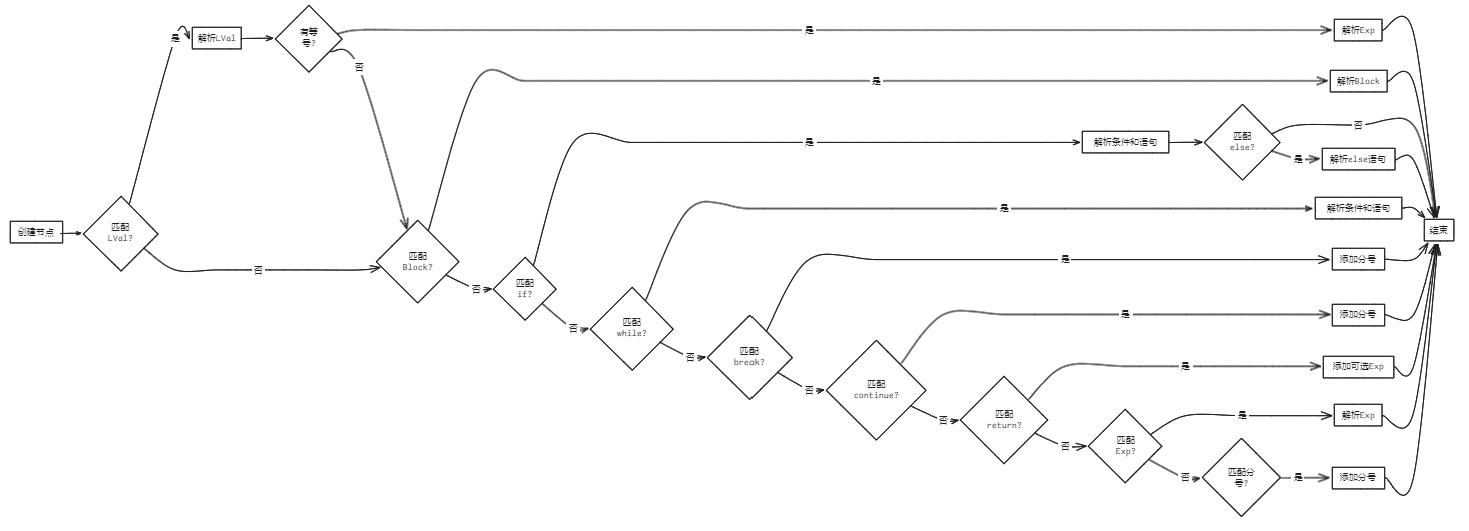
bool Parser::parseStmt(AstNode *root)
{
Stmt *res = new Stmt(root);
saveIndex;
saveChildrenNum;
if (matchLVal().count(token_stream[index].type)) // 匹配LVal '=' Exp ';'
{
parseLVal(res);
if (token_stream[index].type != frontend::TokenType::ASSIGN)
{
undo(lastIndex, res, curChildrenNums); // 不可删除
goto BlockCase;
}
new Term(token_stream[index++], res);
parseExp(res);
new Term(token_stream[index++], res);
return true;
}
BlockCase:
if (matchBlock().count(token_stream[index].type)) // 匹配Block
parseBlock(res);
else if (token_stream[index].type == frontend::TokenType::IFTK) // 匹配'if' '(' Cond ')' Stmt [ 'else' Stmt ]
{
new Term(token_stream[index++], res);
new Term(token_stream[index++], res);
parseCond(res);
new Term(token_stream[index++], res);
parseStmt(res);
if (token_stream[index].type == frontend::TokenType::ELSETK)
{
new Term(token_stream[index++], res);
parseStmt(res);
}
}
else if (token_stream[index].type == frontend::TokenType::WHILETK) // 匹配'while' '(' Cond ')' Stmt
{
new Term(token_stream[index++], res);
new Term(token_stream[index++], res);
parseCond(res);
new Term(token_stream[index++], res);
parseStmt(res);
}
else if (token_stream[index].type == frontend::TokenType::BREAKTK) // 匹配'break' ';'
{
new Term(token_stream[index++], res);
new Term(token_stream[index++], res);
}
else if (token_stream[index].type == frontend::TokenType::CONTINUETK) // 匹配'continue' ';'
{
new Term(token_stream[index++], res);
new Term(token_stream[index++], res);
}
else if (token_stream[index].type == frontend::TokenType::RETURNTK) // 匹配'return' [Exp] ';'
{
new Term(token_stream[index++], res);
if (matchExp().count(token_stream[index].type))
parseExp(res);
new Term(token_stream[index++], res);
}
else if (matchExp().count(token_stream[index].type)) // 匹配[Exp] ';'
{
parseExp(res);
new Term(token_stream[index++], res);
}
else if (token_stream[index].type == frontend::TokenType::SEMICN) // 匹配';'
new Term(token_stream[index++], res);
return true;
}
- 表达式 (Exp)
bool Parser::parseExp(AstNode *root)
{
Exp *res = new Exp(root);
parseAddExp(res);
return true;
}
- 条件表达式 (Cond)
bool Parser::parseCond(AstNode *root)
{
Cond *res = new Cond(root);
parseLOrExp(res);
return true;
}
- 左值表达式 (LVal)
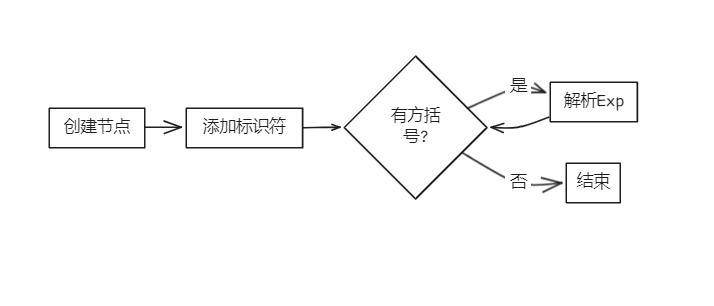
bool Parser::parseLVal(AstNode *root)
{
LVal *res = new LVal(root);
new Term(token_stream[index++], res); // 匹配Ident
while (token_stream[index].type == frontend::TokenType::LBRACK) // 匹配{ '[' Exp ']' }
{
new Term(token_stream[index++], res);
parseExp(res);
new Term(token_stream[index++], res);
}
return true;
}
- 数值 (Number)
bool Parser::parseNumber(AstNode *root)
{
Number *res = new Number(root);
new Term(token_stream[index++], res);
return true;
}
- 基本表达式 (PrimaryExp)
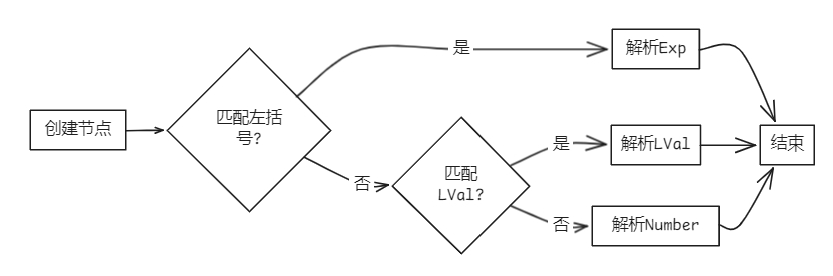
bool Parser::parsePrimaryExp(AstNode *root)
{
PrimaryExp *res = new PrimaryExp(root);
if (token_stream[index].type == frontend::TokenType::LPARENT) // 匹配'(' Exp ')'
{
new Term(token_stream[index++], res);
parseExp(res);
new Term(token_stream[index++], res); // ')'
}
else if (matchLVal().count(token_stream[index].type)) // 匹配LVal
parseLVal(res);
else if (matchNumber().count(token_stream[index].type)) // 匹配Number
parseNumber(res);
return true;
}
- 一元表达式 (UnaryExp)
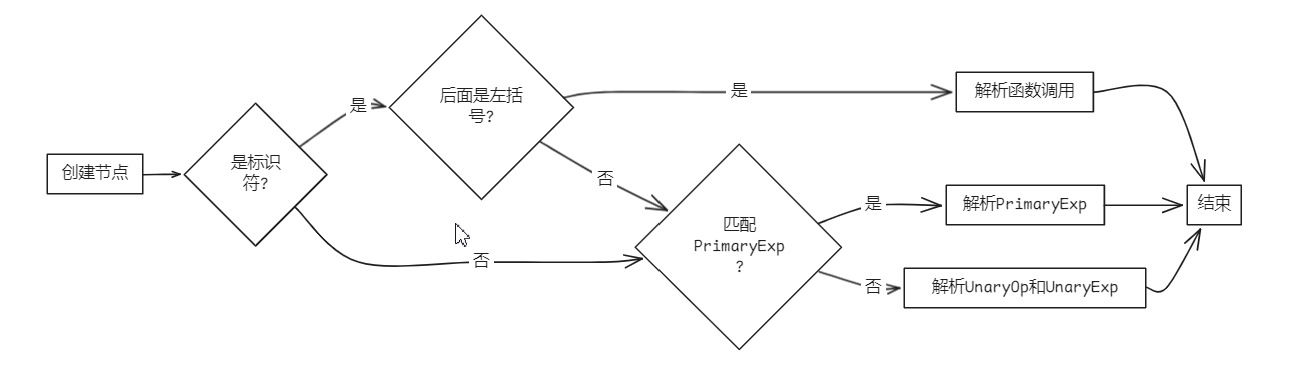
bool Parser::parseUnaryExp(AstNode *root)
{
UnaryExp *res = new UnaryExp(root);
saveIndex;
saveChildrenNum;
if (token_stream[index].type == frontend::TokenType::IDENFR) // 匹配Ident '(' [FuncRParams] ')'
{
new Term(token_stream[index++], res);
if (token_stream[index].type != frontend::TokenType::LPARENT)
{
undo(lastIndex, res, curChildrenNums);
goto PrimaryExpCase;
}
new Term(token_stream[index++], res);
if (matchFuncRParams().count(token_stream[index].type))
parseFuncRParams(res);
new Term(token_stream[index++], res);
return true;
}
PrimaryExpCase:
if (matchPrimaryExp().count(token_stream[index].type)) // 匹配PrimaryExp
{
parsePrimaryExp(res);
return true;
}
if (matchUnaryOp().count(token_stream[index].type)) // 匹配UnaryOp UnaryExp
{
parseUnaryOp(res);
parseUnaryExp(res);
}
return true;
}
- 单目运算符 (UnaryOp)
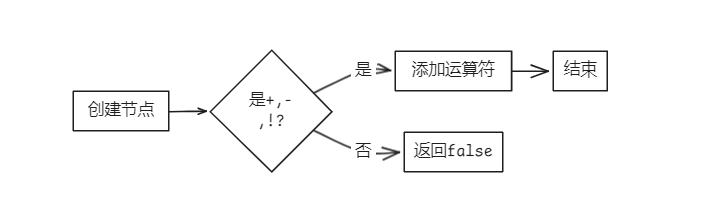
bool Parser::parseUnaryOp(AstNode *root)
{
UnaryOp *res = new UnaryOp(root);
if (token_stream[index].type != frontend::TokenType::PLUS && token_stream[index].type != frontend::TokenType::MINU && token_stream[index].type != frontend::TokenType::NOT)
return false;
new Term(token_stream[index++], res);
return true;
}
- 函数实参表 (FuncRParams)
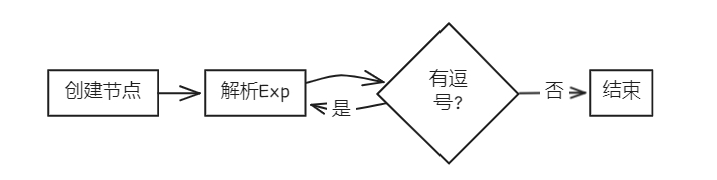
bool Parser::parseFuncRParams(AstNode *root)
{
FuncRParams *res = new FuncRParams(root);
parseExp(res);
while (token_stream[index].type == frontend::TokenType::COMMA)
{
new Term(token_stream[index++], res);
parseExp(res);
}
return true;
}
- 乘除模表达式 (MulExp)
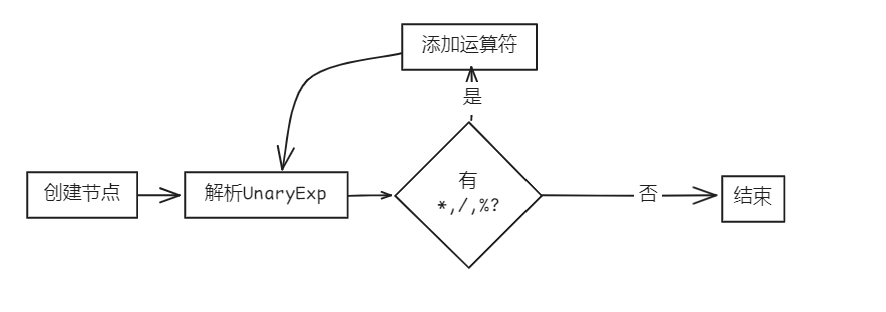
bool Parser::parseMulExp(AstNode *root)
{
MulExp *res = new MulExp(root);
parseUnaryExp(res);
while (token_stream[index].type == frontend::TokenType::MULT || token_stream[index].type == frontend::TokenType::DIV || token_stream[index].type == frontend::TokenType::MOD)
{
new Term(token_stream[index++], res);
parseUnaryExp(res);
}
return true;
}
- 加减表达式 (AddExp)
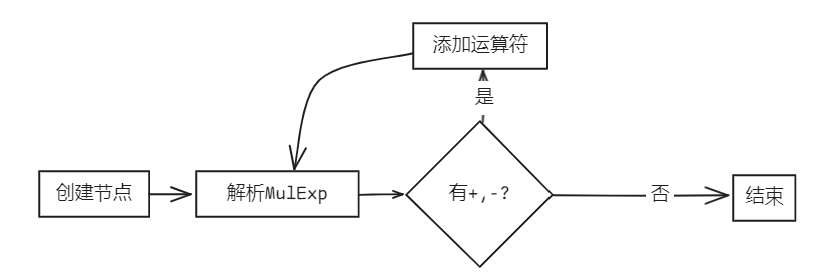
bool Parser::parseAddExp(AstNode *root)
{
AddExp *res = new AddExp(root);
parseMulExp(res);
while (token_stream[index].type == frontend::TokenType::PLUS || token_stream[index].type == frontend::TokenType::MINU)
{
new Term(token_stream[index++], res);
parseMulExp(res);
}
return true;
}
- 关系表达式 (RelExp)
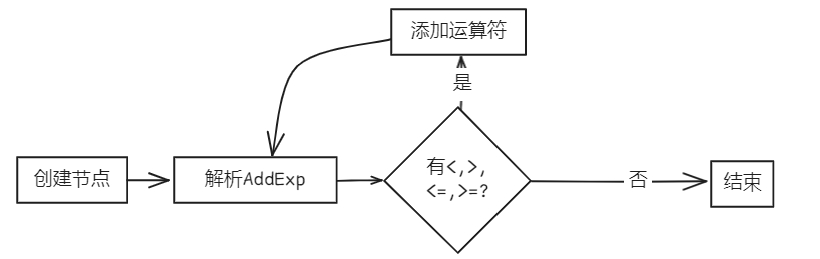
bool Parser::parseRelExp(AstNode *root)
{
RelExp *res = new RelExp(root);
parseAddExp(res);
while (token_stream[index].type == frontend::TokenType::LSS || token_stream[index].type == frontend::TokenType::GTR || token_stream[index].type == frontend::TokenType::LEQ || token_stream[index].type == frontend::TokenType::GEQ)
{
new Term(token_stream[index++], res);
parseAddExp(res);
}
return true;
}
- 相等性表达式 (EqExp)
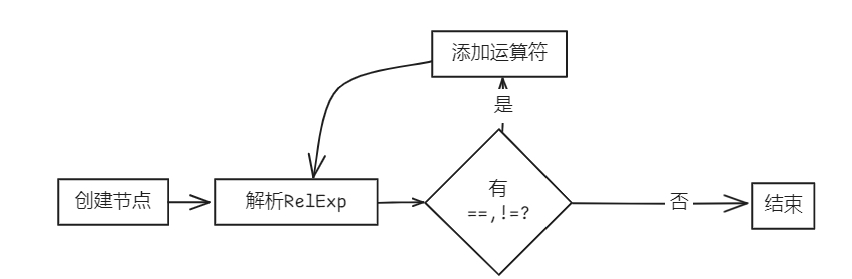
bool Parser::parseEqExp(AstNode *root)
{
EqExp *res = new EqExp(root);
parseRelExp(res);
while (token_stream[index].type == frontend::TokenType::EQL || token_stream[index].type == frontend::TokenType::NEQ)
{
new Term(token_stream[index++], res);
parseRelExp(res);
}
return true;
}
- 逻辑与表达式 (LAndExp)
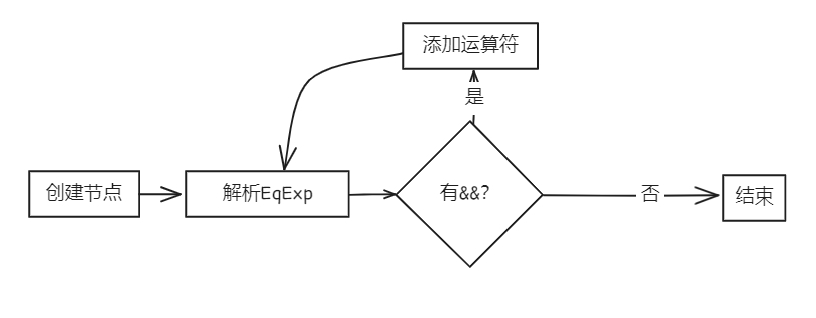
bool Parser::parseLAndExp(AstNode *root)
{
LAndExp *res = new LAndExp(root);
parseEqExp(res);
if (token_stream[index].type == frontend::TokenType::AND)
{
new Term(token_stream[index++], res);
parseLAndExp(res);
}
return true;
}
- 逻辑或表达式 (LOrExp)
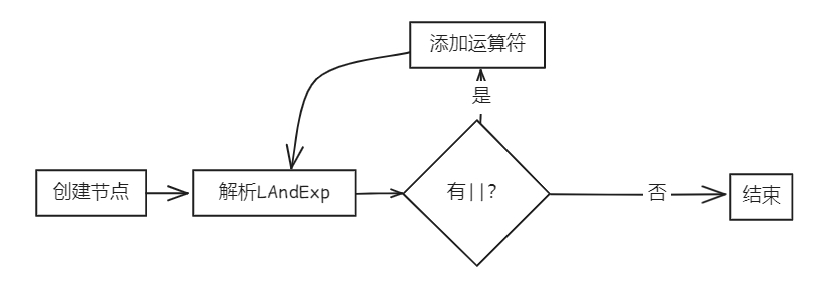
bool Parser::parseLOrExp(AstNode *root)
{
LOrExp *res = new LOrExp(root);
parseLAndExp(res);
if (token_stream[index].type == frontend::TokenType::OR)
{
new Term(token_stream[index++], res);
parseLOrExp(res);
}
return true;
}
- 常量表达式 (ConstExp)
bool Parser::parseConstExp(AstNode *root)
{
ConstExp *res = new ConstExp(root);
parseAddExp(res);
return true;
}
语义分析
实验二的目标是输入实验一的结果抽象语法树,经过语义分析和语法制导翻译,生成中间表示IR。
步骤如下
首先我们在src目录下建立对应的ir文件夹,然后在里面实现对应的头文件中的函数
评论